Log-to-Action
On-Demand Anomaly Analytics with Snowflake Cortex and Word2Vec
A few weeks back, a customer came to me with an interesting problem. They, like many customers, had a massive amount of logs that they were storing for IT incident response. When an incident or outage occurred, they’d ask their analysts to search through them, looking for root causes and explanations. The customer wanted to use AI to help with this and was seeking advice on implementation.
This article is going to explore implementing an approach detailed in the paper LogEvent2Vec mixing in some AI technology for both for pipeline and immediate agentic triage.
An overview of the process
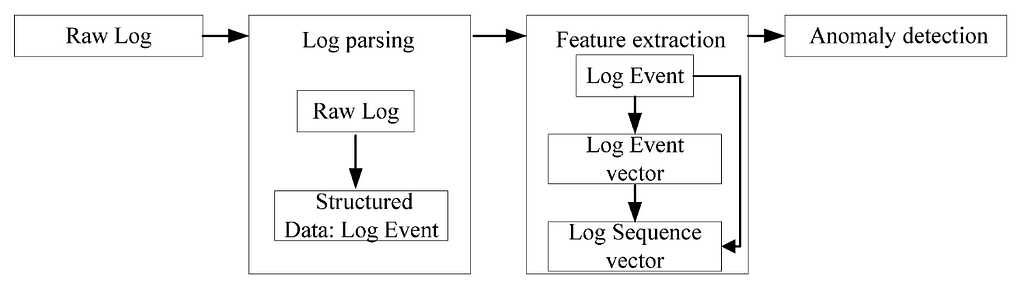
In this solution, we perform anomaly detection not on the logs themselves but rather on the ID of a log template. This means that both the embedding and anomaly detection process are able to be done at scale and with speed. Furthermore, by incorporating AI into the process, two time consuming manual processes (creating the config and triaging the results) can be greatly automated.
Parsing
The first step is to parse our logs into templates. Theoretically any template parser could be used but since we are following the paper, we stick with Drain. This means that we want to generalize our logs so that a specific log such as
Jun 26 09:13:01 combo ftpd[12345]: connection from 192.293.193.11 () at Sun Jun 26 09:13:01 2025
Becomes
<> combo ftpd[<*>]: connection from <*>() at <*>
And then group similar log templates into clusters.
This technique will reduce the number of unique logs that we’ll look at significantly. When testing against a set from the Loghub project (2). It reduced the number of unique logs from >25,000 to around 200.
To configure this parser, we rely on regex for creating the masks. We start with some generic regex like timestamps but because we don’t know until we start what types of logs we’re looking at, we will need to generate a custom config on the fly. This is where we use LLMs. Snowflake, through Cortex, exposes a variety of first and third party LLM models via SQL and Python, we use Cortex to generate a custom config.
def _build_prompt(self, log_samples: List[str]) -> str:
"""Build the LLM prompt with log samples."""
sample_text = "\n".join(log_samples[:50])
prompt = f"""Analyze the following log lines and identify DOMAIN-SPECIFIC variable patterns that should be masked.
DO NOT include generic patterns like:
- Numbers (handled by base masking)
- IP addresses (handled by base masking)
- File paths starting with / (handled by base masking)
- Hex values like 0x... (handled by base masking)
ONLY identify domain-specific patterns unique to these logs, such as:
- Session IDs or tokens (e.g., session_123abc)
- Database/transaction IDs
- User IDs or usernames in specific formats
- Custom error codes
- API endpoints or URLs
- Process names with specific patterns
- Application-specific identifiers
LOG SAMPLES:
{sample_text}
Provide your response as a JSON array of objects, each with:
- "regex_pattern": A Python regex pattern to match the variable (use proper escaping)
- "mask_with": A descriptive name for what's being masked (e.g., "SESSION_ID", "USER_ID")
Example format:
[
{{"regex_pattern": "session_[a-z0-9]+", "mask_with": "SESSION_ID"}},
{{"regex_pattern": "user=[a-zA-Z]+", "mask_with": "USERNAME"}}
]
Return ONLY the JSON array, no other text."""
return prompt
We then assign each template a unique ID. The rest of our analysis will use the IDs, instead of the raw logs.
Parsing logs to extract templates…
✓ Loaded 9 domain-specific patterns from drain_config.json
Discovered 218 unique log events/templates:
E0: <*> combo syslogd 1.4.1: restart. (count: 42)
E1: <*> combo syslog: syslogd startup succeeded (count: 415)
E2: <*> combo kernel: klogd 1.4.1, log source = <*> started. (count: 9)
E3: <*> combo kernel: Linux version <*>(gcc version <*> <*> (Red Hat Linux <*> #1 Sat May <*> <*> EDT <*> (count: 8)
E4: <*> combo kernel: BIOS-provided physical RAM map: (count: 8)
E5: <*> combo kernel: <*> <*> - <*> (usable) (count: 178)
E6: <*> combo kernel: 0MB HIGHMEM available. (count: 205)
This again makes it easier to do embeddings, but also in this case makes sense. We don’t really care about the contents of the logs but rather how they relate to each other. For instance if we map
L1: Login Attempt Failed
L2: Login Attempt Succeeded
A normal pattern may be L2,L2,L1,L2 but if we see L1 for 100 times. We may be looking at a brute force attempt (and if we see an L2 at the end maybe that means it succeeded!). All this to say we will need to combine our logs into sequences.
Creating sequences
This is a pretty straightforward step, we just need to group the IDs together. If we’d like we can create some overlap between the sequences but for now lets just create discrete chunks. The paper creates chunks of 5000 logs but for testing lets just set the window size to 50.
def create_sequences(event_ids, window_size=100):
"""
Create fixed-size sequences from log events.
Args:
event_ids: List of log event IDs
window_size: Number of log events per sequence
Returns:
sequences: List of event ID sequences
"""
sequences = []
for i in range(0, len(event_ids) - window_size + 1, window_size):
# Get sequence
seq = event_ids[i:i+window_size]
sequences.append(seq)
return sequences
# Adjust window size based on dataset size
WINDOW_SIZE = 50
print(f"Creating sequences with window size {WINDOW_SIZE}...")
sequences = create_sequences(
df['event_id'].tolist(),
window_size=WINDOW_SIZE
)
Event Vectors using word2vec
The paper, logEvent2Vec is a play on words based on the Word2Vec technique. Word2Vec creates what’s known as static embeddings. This means that when words are embedded every word will have the same vector or numerical representation. For example, “Where is the dog” might map to “1.2, 4.5, 6.4, 4.5”. However the word “dog” is always mapped to 4.5, this means that while we can mathematically analyze words as they relate to the word dog, we still can’t determine for sure, what type of “dog” they mean.
This is why using an LLM vectorization model creates what’s known as “contextual embeddings”. In layman’s terms, it means that we can now tell the difference between “walking a dog” and “eating a hot dog”.
This is a common technique for certain types of log based anomaly detection use cases. Logbert, for instance, uses the contextual embedding BERT technique for anomaly detection. In fact, one of Snowflake’s startup challenge finalists last year was a company called DeepTempo. They use a similar technique to look for anomalies in network logs and are deployed in Snowflake as a native app. This means that it does all its training inside of a customer’s Snowflake account so data never has to leave.
For this case, however, there are some tradeoffs to consider. The biggest is that a context based technique will take a long time to train. This is great when we’re looking at a single log source over time (think network logs) . When we’re trying to quickly search though some arbitrary logs we’ve never seen before however, we want to be faster. Furthermore, Logbert type methods require a baseline set to train on and in this use case we want to take a look at data that we may have never seen before. For these reasons we’re going to be using a static method based on Word2Vec.
Word2Vec creates embeddings on a very small set of words. Actually a sentence. A good way to think about it is that it takes a sentence and tries to figure out how all the words in that sentence relate to each other. There are two ways it does this, Continuous bag of words (CBOW) and Skip-Gram. Both are essentially two sides of the same coin. With CBOW the technique looks at all the surrounding words in a sentence and tries to “guess” the missing one.
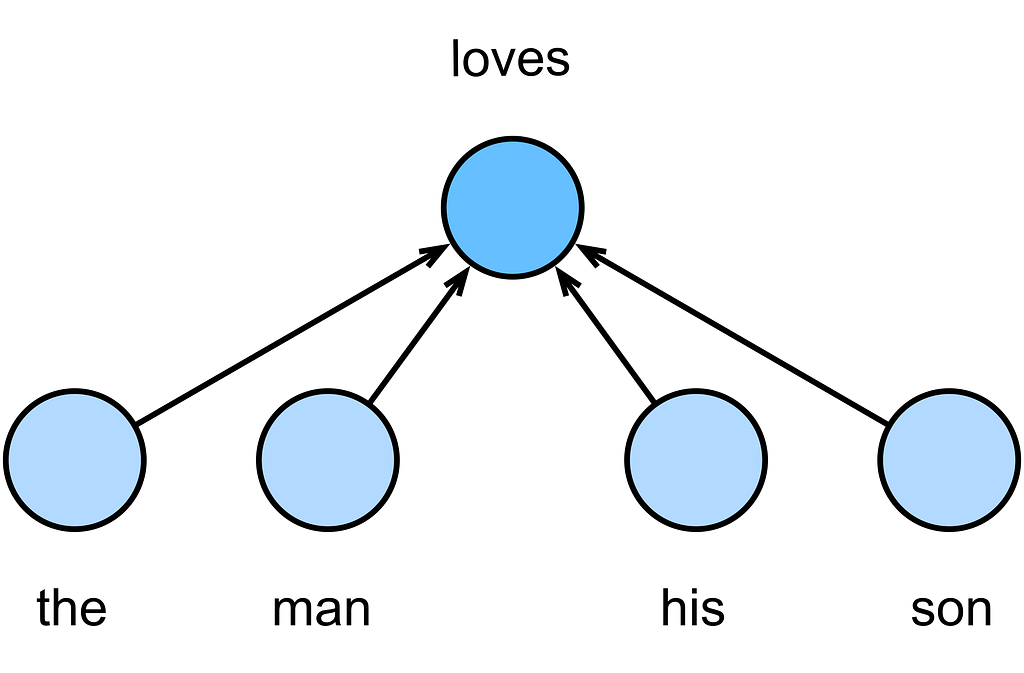
Skip-Gram is the opposite, it takes in a single word and tries to “guess” the surrounding words.
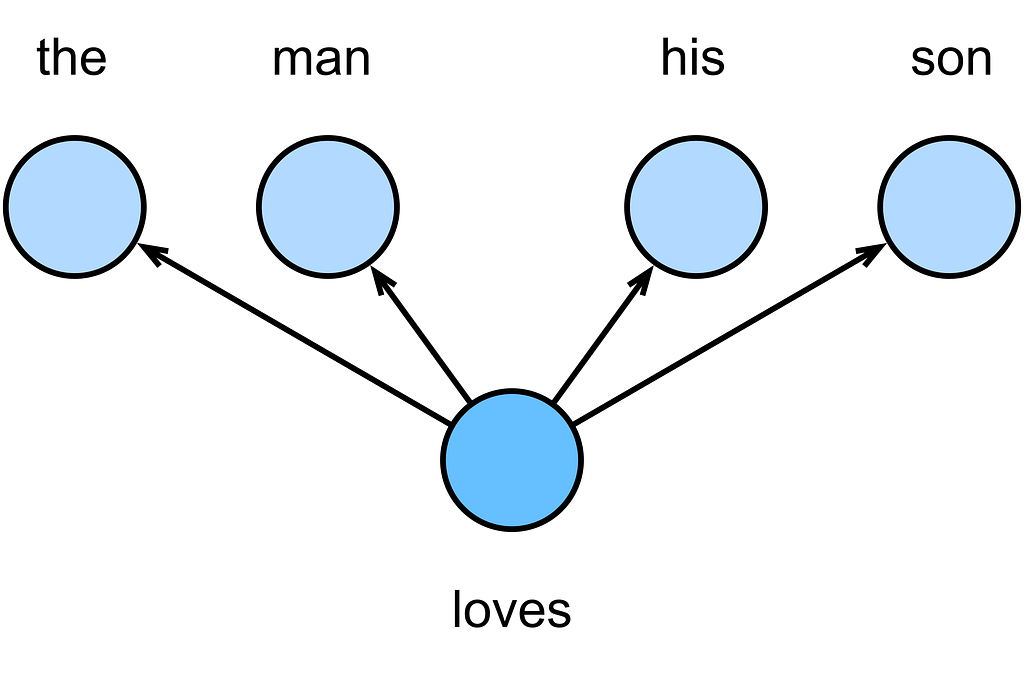
The core insight the authors of logEvent2Vec looked into, was what would happen if instead of a words in a sentence, we look at logs in sequence! They use CBOW so that’s what we’ll do.
It looks something like this
model = Word2Vec(
sentences=sequences,
vector_size=vector_size,
window=window,
min_count=min_count,
sg=0, # CBOW model (sg=1 for skip-gram)
workers=4,
epochs=epochs,
seed=42
)
We run it and get outputs like this:
Training Word2Vec on log events...
Vector size: 20
Window: 5
Epochs: 10
Training completed in 0.03 seconds
Generated embeddings for 218 log events
Sample event embeddings:
E198: [-0.1578253 -0.03097212 0.512029 0.13182822 1.3751203 ]... (truncated)
Template: <*> combo kernel: Out of Memory: Killed process <*> (httpd).
E147: [-1.499062 -0.30853173 -0.8044181 2.4029365 2.0406165 ]... (truncated)
Template: <*> combo ftpd[4301]: connection from <*> () at Sat Jun <*> <*> <*>
Sequence Vectors
So now, we have event vectors. We can look at any given sequence and see what individual events stand out. A good start, but what we really want is to figure out which sequences are the ones that stand out.
The paper discusses two techniques for creating sequence vectors. Barycentric and TF-IDF. Without going into the semantics the core difference is that Barycentric just takes a “simple” average of all events to create a sequence vector. TF-IDF has weight, which means “rare” events are treated as more important. Intuitively one may think that TF-IDF is more useful for anomaly detection but it does depend on your use case.
Anomaly detection
Now we have everything converted to vectors we can run an ML model for anomaly detection. There’s a bunch of options out there and the paper doesn’t have an opinion. So we’ll run an isolation forest model using Sci-kit which is already loaded into Snowflake. Isolation forest is an algorithm for anomaly detection. Its “unsupervised” which means the data does need to be labeled which of course is a requirement for this task. We run it and get the following
====================================================================================================
TOP 10 MOST ANOMALOUS SEQUENCES (Lowest Anomaly Scores)
====================================================================================================
🔴 FLAGGED Rank #1 - Sequence #428
Anomaly Score: -0.6836
----------------------------------------------------------------------------------------------------
📋 Event Distribution (top 3):
E120: 43x - <*> combo udev[2054]: creating device node '/udev/lp0'...
E136: 2x - <*> combo named[2275]: couldn't add command channel <*> not found...
E1: 1x - <*> combo syslog: syslogd startup succeeded...
📄 First 5 ORIGINAL logs in sequence:
[1] Dec 6 12:24:32 combo mysqld: Starting MySQL: succeeded...
[2] Dec 6 17:24:32 combo named[2298]: couldn't add command channel 127.0.0.1#953: not found...
[3] Dec 6 17:24:33 combo named[2298]: couldn't add command channel ::1#953: not found...
[4] Dec 6 12:24:33 combo rsyncd[2386]: rsyncd version 2.6.2 starting, listening on port 873...
[5] Dec 6 17:24:34 combo named[2298]: running…
Ok great, we’ve identified anomalous behavior but now we’re faced with the age old question that professionals have been asking whenever they are faced with anomaly detection. Ok so that’s unique, so what?!
Agentic Triage
I’ve written in the past about agentic triage. In the security and SRE world we’re constantly faced with signals. Just because something is unique or interesting doesn’t mean it has value. We need to have it in context. A service may not restart often but if it doesn’t cause downtime we don’t care. Using Cortex Complete we can pass the results and the raw logs they correspond to into an LLM and get back something useful. We try the following prompt
system_message = ("You are an expert in log analysis, cybersecurity, and system administration. "
"You help identify and explain anomalies in system logs.")
user_prompt = f"""You are a cybersecurity and system administration expert analyzing anomalous log sequences.
I've detected an anomalous sequence of logs (Rank #{rank}, Anomaly Score: {anomaly_score:.4f}) using Isolation Forest.
**Log Event Distribution (top 5):**
{event_summary}
**Raw Logs from this sequence:**
{log_text}
Please analyze these logs and provide:
1. **TITLE** (max 10 words): A concise, descriptive title for this anomaly
2. **DESCRIPTION** (3-5 sentences): Explain:
- What is happening in these logs?
- Why might this sequence be anomalous?
- What could be the potential security or operational implications?
- Is this likely benign (e.g., system restart, maintenance) or concerning (e.g., attack, system failure)?
Respond in the following JSON format:
{{
"title": "Your concise title here",
"description": "Your detailed description here"
}}
Return ONLY the JSON, no other text."""And now get back something useful
====================================================================================================
🤖 LLM ANALYSIS RESULTS - ANOMALY TITLES & DESCRIPTIONS
====================================================================================================
\n====================================================================================================
🔴 RANK #1 - SEQUENCE #428
Anomaly Score: -0.6836
====================================================================================================
\n📌 TITLE:
Rapid Device Node Creation/Removal with Named Server Issues
\n📝 DESCRIPTION:
The logs show an intense burst of udev activity creating and removing virtual console
device nodes (/dev/vcs*), coupled with named (DNS) server initialization errors on both
IPv4 and IPv6 command channels. The sequence appears anomalous due to the unusually
high frequency of device node operations and the DNS server's failure to establish
command channels. While the udev activity suggests a system reconfiguration or restart,
the named server issues could impact DNS resolution capabilities. This pattern is
likely benign and related to a system restart or service reconfiguration, though the
named server errors warrant investigation to ensure proper DNS functionality.
Putting it all together
At this point, I use AI. I have a working notebook using Snowflake. I ask my IDE to create me a Streamlit app and now we have something! We have an uploader, an explorer and the ability to look at the raw logs
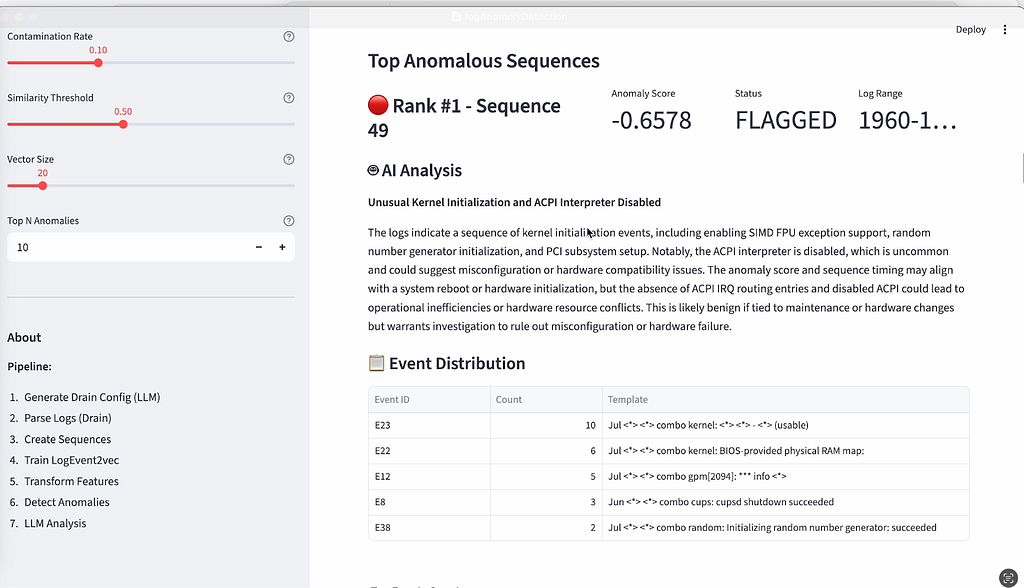
All this to show an interesting but certainly not unique use case on Snowflake. MSSPs like eSentire or platforms like Tenable are building their high scale analytics and AI use cases directly on Snowflake or go directly to our AI Data Cloud for Cybersecurity Page to learn more.
Citations
1. Wang, J., Tang, Y., He, S., Zhao, C., Sharma, P. K., Alfarraj, O., & Tolba, A. (2020). LogEvent2vec: LogEvent-to-Vector Based Anomaly Detection for Large-Scale Logs in Internet of Things. Sensors, 20(9), 2451. https://doi.org/10.3390/s20092451
2. Jieming Zhu, Shilin He, Pinjia He, Jinyang Liu, Michael R. Lyu. Loghub: A Large
Collection of System Log Datasets for AI-driven Log Analytics. In ISSRE, 2023.
https://github.com/logpai/loghub
3. H. Guo, S. Yuan and X. Wu, “LogBERT: Log Anomaly Detection via BERT,” 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 2021, pp. 1–8, doi: 10.1109/IJCNN52387.2021.9534113.
keywords: {Training;Computational modeling;Bit error rate;Neural networks;Transformers;Minimization;Natural language processing},
https://ieeexplore.ieee.org/document/9534113
4. Zhang, Aston and Lipton, Zachary C. and Li, Mu and Smola, Alexander J. — https://github.com/d2l-ai/d2l-en, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=152266485
This article originally appeared on Medium.